Adding a robots.txt using Cloudflare workers
I got an unexpected traffic spike to https://russian-ira-facebook-ads.datasettes.com/ - which runs on Cloud Run - and decided to use robots.txt to block crawlers.
Re-deploying that instance was a little hard because I didn't have a clean repeatable deployment script in place for it (it's an older project) - so I decided to try using Cloudflare workers for this instead.
DNS was already running through Cloudflare, so switching it to "proxy" mode to enable Cloudflare caching and workers could be done in the Cloudflare control panel.

I navigated to the "Workers" section of the Cloudflare dashboard and clicked "Create a Service", then used their "Introduction (HTTP handler)" starting template. I modified it to look like this and saved it as block-all-robots:
addEventListener("fetch", (event) => {
event.respondWith(
handleRequest(event.request).catch(
(err) => new Response(err.stack, { status: 500 })
)
);
});
async function handleRequest(request) {
const { pathname } = new URL(request.url);
if (pathname == "/robots.txt") {
return new Response("User-agent: *\nDisallow: /", {
headers: { "Content-Type": "text/plain" },
});
}
}After deploying it, https://block-all-robots.simonw.workers.dev/robots.txt started serving my new robots.txt file:
User-agent: *
Disallow: /
Then in the Cloudflare dashboard for datasettes.com I found the "Workers" section (not to be confused with the "Workers" section where you create and edit workers) I clicked "Add route" and used the following settings:
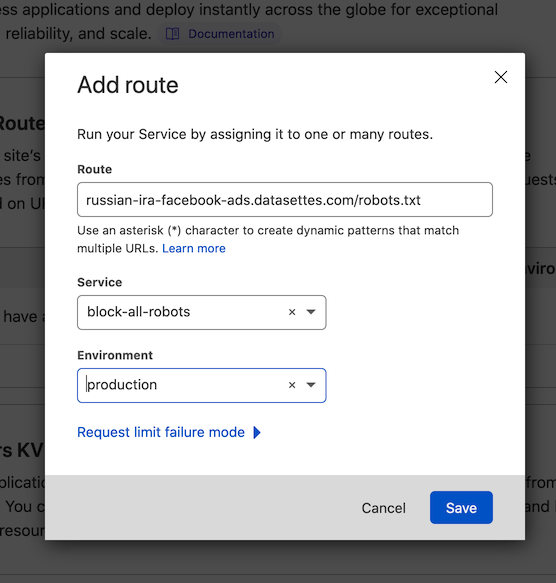
Route: russian-ira-facebook-ads.datasettes.com/robots.txt
Service: block-all-robots
Environment: production
I clicked "Save" and https://russian-ira-facebook-ads.datasettes.com/robots.txt instantly started serving the new file.
Related
Created 2021-12-21T15:07:51-08:00 · Edit