How to read Hacker News threads with most recent comments first
Hacker News displays comments in a tree. This can be frustrating if you want to keep track of a particular conversation, as you constantly have to seek through the tree to find the latest comment.
I solved this problem in three different ways today. I'll detail them in increasing orders of complexity (which frustratingly is the reverse order to how I figured them out!)
The easiest way: Algolia search
The official Hacker News search uses Algolia, with a constantly updated index.
If you search for story:35111646, filter for comments and then order by date you'll get the comments for that particular story, most recent at the top. Problem solved!
Here's the URL - edit the story ID in that URL (or on the page) to view comments for a different story.

The Algolia search_by_date API
The Algolia Hacker News API is documented here: https://hn.algolia.com/api
Note that this is a separate system from the official Hacker News API, which is powered by Firebase, doesn't provide any search or filtering endpoints and is documented at https://github.com/HackerNews/API
To retrieve all comments on a specific story ordered by date, most recent first as JSON you can hit this endpoint:
https://hn.algolia.com/api/v1/search_by_date?tags=comment,story_35111646&hitsPerPage=1000
The tags= parameter does all of the work here - we're asking it for items of type comment that have been tagged with story_35111646.
This returns 20 results by default. I've added &hitsPerPage=1000 to get back the maximum of 1,000.
This gives you back JSON, but how can we turn that into something that's more readable in our browser?
Loading that into Datasette Lite
I'm going to use Datasette Lite, my build of Datasette running directly in the browser using Python compiled to WebAssembly. More on how that works here.
This is possible because the Algolia API returns JSON with a access-control-allow-origin: * CORS header, allowing that data to be loaded by other web applications running on different domains.
If you pass Datasette Lite a ?json= parameter with the URL to a JSON file that returns a list of objects, it will use sqlite-utils to load that JSON into a SQLite table with a column for each of the keys in those objects.
This URL loads that data:
We can navigate to the search_by_date table to browse and filter the comments.
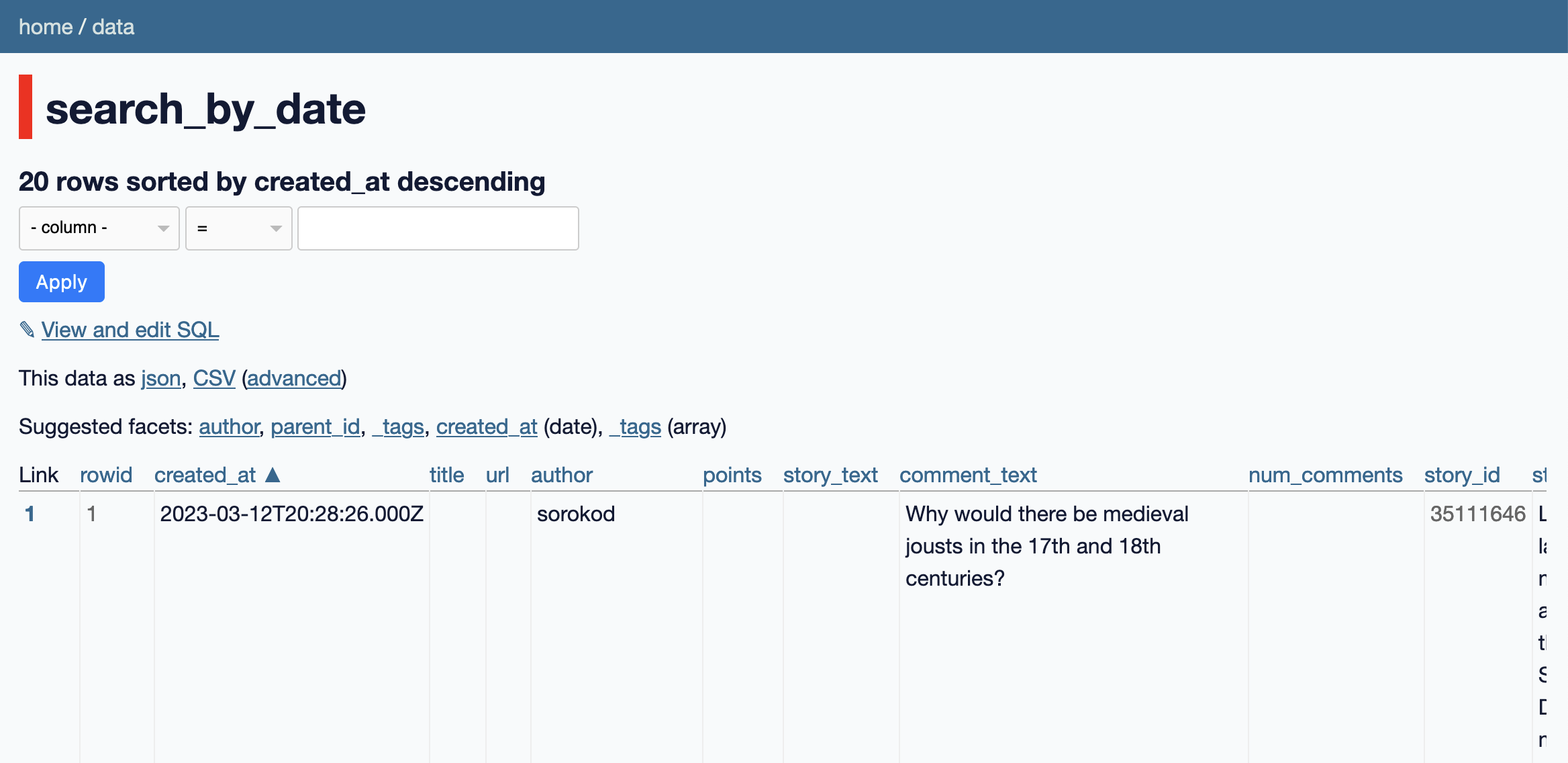
Let's make some improvements to how it's displayed using a custom SQL query and some Datasette plugins.
Datasette Lite supports some Datasette plugins - you can add ?install=name-of-plugin to the URL to install them directly from PyPI.
I'm going to load two plugins:
- datasette-simple-html adds SQL functions for escaping and unescaping HTML text and stripping tags
- datasette-json-html provides a mechanism for outputting custom links in column results
Here's a URL that loads those two plugins:
Now here's a custom SQL query that makes the comments a bit nicer to read when they are displayed by Datasette:
select
created_at,
author,
html_unescape(
html_strip_tags(comment_text)
) as text,
parent_id,
_tags
from
search_by_date
order by
created_at descThis link will execute that SQL query against the data in Datasette Lite.
One last trick: it would be neat if we could click through from the results to the comment on Hacker News. Here's how to add that, using a trick enabled by datasette-json-html:
select
json_object(
'label', objectID,
'href', 'https://news.ycombinator.com/item?id=' || objectID
) as link,
created_at,
author,
html_unescape(
html_strip_tags(comment_text)
) as text,
parent_id,
_tags
from
search_by_date
order by
created_at descThis adds link to each comment as the first column in the table.
It works by building a JSON string {"label": "35123521", "href": "https://news.ycombinator.com/item?id=35123521"} - the plugin then renders that as a link when the table is displayed, using Datasette's render_cell() plugin hook.

The most complicated solution, with json_tree()
My first attempt at solving this was by far the most complex.
Before I explored the search_by_date API I spotted that Algolia offers a items API, which returns ALL of the content for a thread in a giant nested JSON object:
https://hn.algolia.com/api/v1/items/35111646
Try that now and you'll see that the top level object has this shape {"id": ..., "children": [...]} - with that `"children" array containing a further nested array of objects representing the whole thread.
Datasette Lite's ?json= parameter expects an array of objects. But... if you give it a top-level object which has a key that is itself an array of objects, it will load the objects from that array instead.
Which means passing it the above URL results in a table with a row for each of the top-level comments on that item... plus a children column with the JSON string of each of their descendents.
You can try that here:
https://lite.datasette.io/?json=https://hn.algolia.com/api/v1/items/35111646
SQLite has a robust suite of JSON functions, plus the ability to execute recursive CTEs - surely it would be possible to write a query that flattens that nested structure into a table with a row for each comment?
I spent quite a bit of time on this. Eventually I realized that you don't even need a recursive CTE for this - you can use the json_tree() function provided by SQLite instead.
Here's the query I came up with:
with items as (select * from [35111646]),
results as (
select
json_extract(value, '$.id') as id,
json_extract(value, '$.created_at') as created_at,
json_extract(value, '$.author') as author,
html_strip_tags(html_unescape(json_extract(value, '$.text'))) as text,
json_extract(value, '$.parent_id') as parent_id
from
items, json_tree(items.children) tree
where
tree.type = 'object'
union all
select id, created_at, author, html_strip_tags(html_unescape(text)) as text, parent_id
from items
)
select
json_object('label', id, 'href', 'https://news.ycombinator.com/item?id=' || id) as link,
*
from results order by created_at desc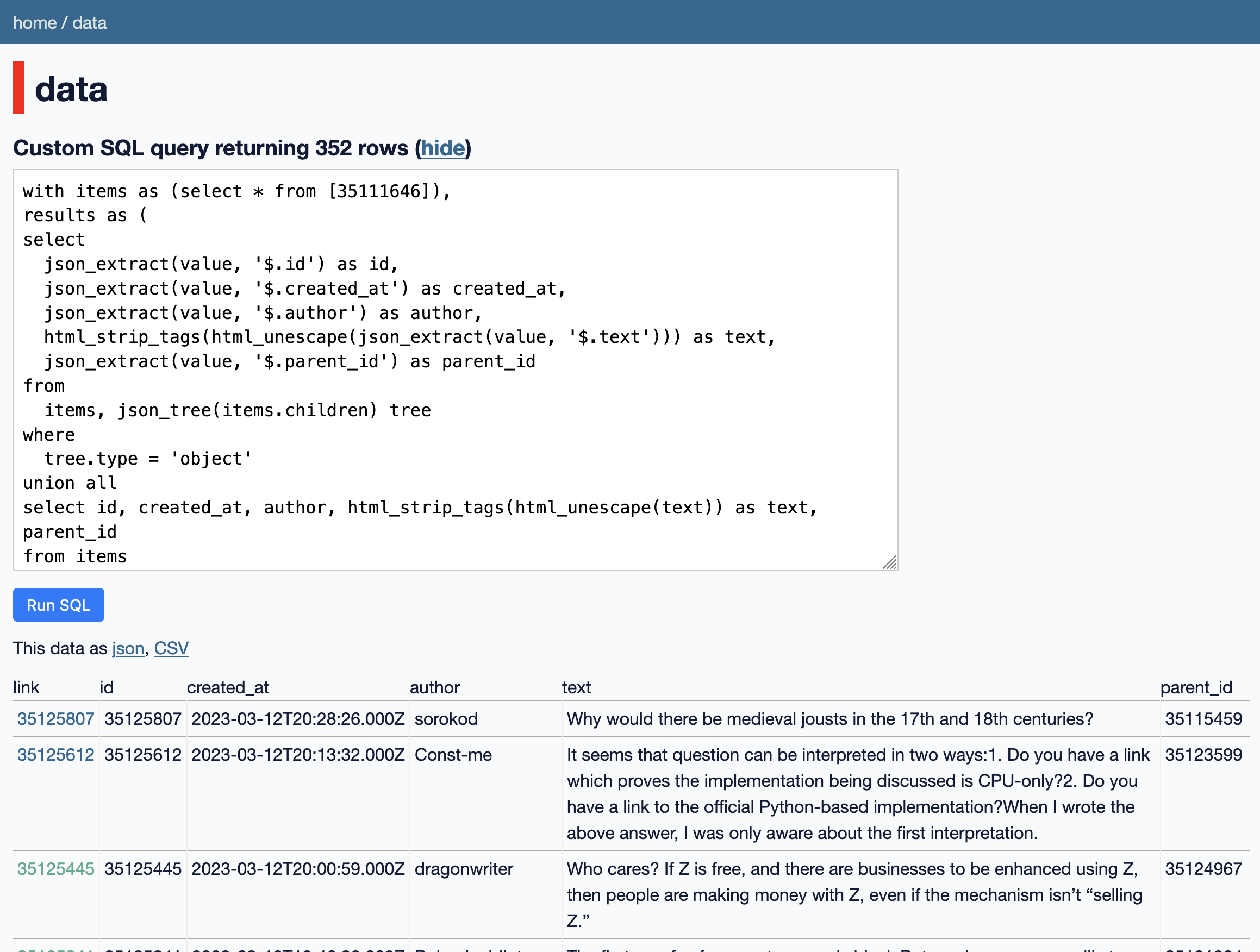
The key to understanding the above is to understand how json_tree() works. Given a JSON value it returns a huge virtual table representing every node in that tree as a flat list.
Here's a simple example:
select * from json_tree('[
{
"id": 1,
"name": "A",
"children": [
{
"id": 2,
"name": "B"
}
]
},
{
"id": 3,
"name": "C"
}
]')Try that against Datasette. The output looks like this:
| key | value | type | atom | id | parent | fullkey | path |
|---|---|---|---|---|---|---|---|
| [{"id":1,"name":"A","children":[{"id":2,"name":"B"}]},{"id":3,"name":"C"}] | array | 0 | $ | $ | |||
| 0 | {"id":1,"name":"A","children":[{"id":2,"name":"B"}]} | object | 1 | 0 | $[0] | $ | |
| id | 1 | integer | 1 | 3 | 1 | $[0].id | $[0] |
| name | A | text | A | 5 | 1 | $[0].name | $[0] |
| children | [{"id":2,"name":"B"}] | array | 7 | 1 | $[0].children | $[0] | |
| 0 | {"id":2,"name":"B"} | object | 8 | 7 | $[0].children[0] | $[0].children | |
| id | 2 | integer | 2 | 10 | 8 | $[0].children[0].id | $[0].children[0] |
| name | B | text | B | 12 | 8 | $[0].children[0].name | $[0].children[0] |
| 1 | {"id":3,"name":"C"} | object | 13 | 0 | $[1] | $ | |
| id | 3 | integer | 3 | 15 | 13 | $[1].id | $[1] |
| name | C | text | C | 17 | 13 | $[1].name | $[1] |
This is pretty useful! The complex nested object has been flattened for us. Most of these rows aren't relevant... but if we filter for type = 'object' we can get hold of just the nested items within that structure that are complete JSON objects.
So that's what my bigger query does. I call json_tree() on the children column for each of those top level objects, then filter for object within that to get out the nested comments.
Then at the end I do a union all against the top level rows, to ensure they are included in the resulting table.
I was really happy with this query! And then I read a bit more of the Algolia API documentation and realized that it was entirely unneccessary for solving this problem. But I did at least get to learn how to use json_tree().
My original solution: hacker-news-to-sqlite
Prior to today I've solved this problem using my hacker-news-to-sqlite CLI tool instead.
This can suck all of the comments for a thread into a SQLite database, so you can sort them chronologically using Datasette.
To run that command:
pipx install hacker-news-to-sqlite
hacker-news-to-sqlite trees comments.db 35111646
Then open it in Datasette (or Datasette Desktop):
datasette comments.db
hacker-news-to-sqlite uses the original Hacker News API, which means it has to fetch each comment in turn and then fetch any child comments as separate requests - so it takes a while to run!
I'm going to stick with the Algolia solution in the future.
Related
Created 2023-03-12T13:41:22-07:00, updated 2023-03-12T14:40:11-07:00 · History · Edit