Running nanoGPT on a MacBook M2 to generate terrible Shakespeare
nanoGPT is Andrej Karpathy's "simplest, fastest repository for training/finetuning medium-sized GPTs".
His two hour YouTube video Let's build GPT: from scratch, in code, spelled out provides valuable context for understanding how this kind of thing works.
I decided to try running it on my new M2 MacBook Pro.
Setup
The README has a section i only have a macbook - I mostly followed the steps there.
I'm using Python 3.10 installed using Homebrew. I created a fresh virtual environment:
mkdir nanopgt-m2
cd nanopgt-m2/
/opt/homebrew/bin/python3 -m venv venv
source venv/bin/activate
Then installed the dependencies:
pip install transformers datasets tiktoken tqdm wandb numpy
We're going to use a special version of PyTorch that adds support for the M1 and M2 chips (tip from this issue):
pip install \
--pre torch torchvision torchaudio \
--extra-index-url https://download.pytorch.org/whl/nightly/cpu
Now clone the repo:
git clone https://github.com/karpathy/nanoGPT
The prepare.py script downloads the Shakespeare data and splits it into training and validation sets:
cd nanoGPT/data/shakespeare
python prepare.py
Output:
train has 301,966 tokens
val has 36,059 tokens
This created binary train.bin and val.bin files in that folder.
Next change back up to the nanoGPT directory and run the command to train the model:
time python train.py \
--dataset=shakespeare \
--n_layer=4 \
--n_head=4 \
--n_embd=64 \
--compile=False \
--eval_iters=1 \
--block_size=64 \
--batch_size=8 \
--device=cpu
That last line is the most important: if you set it to --device cpu it will run the training entirely on your CPU, which looks like this:
step 0: train loss 10.8340, val loss 10.8173
iter 0: loss 10.8320, time 553.68ms
iter 1: loss 10.8206, time 414.96ms
iter 2: loss 10.8160, time 413.59ms
iter 3: loss 10.8250, time 412.65ms
iter 4: loss 10.8312, time 412.96ms
iter 5: loss 10.8306, time 413.87ms
BUT if you switch that for --device=mps it will use "Metal Performance Shaders", an M1/M2-specific feature. That output looks like this:
step 0: train loss 10.8340, val loss 10.8173
iter 0: loss 10.8320, time 472.43ms
iter 1: loss 10.8206, time 137.21ms
iter 2: loss 10.8160, time 244.42ms
iter 3: loss 10.8250, time 145.10ms
iter 4: loss 10.8312, time 140.41ms
iter 5: loss 10.8306, time 135.30ms
That's a 3x performance improvement!
This command appears to run forever. You can hit Ctrl+C to stop it when you're bored.
The first time I ran it I left it going on CPU overnight and got to this point:
iter 142862: loss 2.1802, time 427.60ms
So that's 142,862 iterations, which took around 11 hours.
The second time I ran it I used --device=mps and stopped it after 6,184 iterations, at a loss of 3.2523. This only took 3.5 minutes.
The model itself is a 39MB file in out/ckpt.pt - this is a checkpoint, which is saved frequently while the training runs.
Generating text
The sample.py file in the nanoGPT repo can be used to generate text from the model.
Before running it, you need to make one edit. You need to change the following line:
device = 'cuda' # examples: 'cpu', 'cuda', 'cuda:0', 'cuda:1', etc.To instead use this:
device = 'cpu'I tried mps here too but it didn't work - I got this error:
File "/Users/simon/Dropbox/Development/nano-gpt-m2/nanoGPT/model.py", line 326, in generate
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
RuntimeError: Currently topk on mps works only for k<=16
Using cpu was plenty fast enough for this though - it's a much easier operation than training the model.
Running python sample.py starts outputting garbage made up Shakespeare! Here's output from my shorter trained mps model:
number of parameters: 3.42M
No meta.pkl found, assuming GPT-2 encodings...
YORK:
'Tis good traitor to thyself and welcome home:
Thou wert thou both, but to greet me the truth.
KING HENRY VI:
As thou wilt, all hope of need is done,
If not so am not committed for my suit.
QUEEN MARGARET:
Now then I have do love the king'st of thee.
Ghost ofORD:
Clarence, and I.
GLOUCESTER:
CLARENCE:
QUEEN ELIZABETH:
Ay, for I had not leave of this grace
To help him and will defend us Duke of York.
KING RICHARD III:
Yield, young Edward, Henry, and henceforth be,
That Edward will be satisfied, for a sin is Romeo.
QUEEN ELIZABETH:
Myself my soul is left by me and all God's.
KING RICHARD III:
Save lords, there no more that way I will speak:
And I am little better more than the world,
That I do see thee sith that royal father
Is not a thousand fearful threatening change:
Let me show me think that I did think
A sin in the other's corse where I have done
Than is but a kinsmen, you will not go:
But yet she, that is she knew my uncle?
It's utter rubbish, but it definitely looks a bit like Shapespeare!
This also goes on forever until you hit Ctrl+C to stop it.
A custom prompt
If you want to start with your own custom text, you can edit the sample.py file and set the start variable. It defaults to start = '\n' - so I changed it to:
start = """
GLOUCESTER:
What do you think of this, my lord?
KING RICHARD II:
"""
Then ran python sample.py and got the following:
number of parameters: 3.42M
No meta.pkl found, assuming GPT-2 encodings...
GLOUCESTER:
What do you think of this, my lord?
KING RICHARD II:
Yea, and for what to give you to jest?
DUCHESS OF YORK:
I amiss, I'll deny it.
DUKE OF YORK:
I am the matter, I beseech your grace
Withalness to be your good queen;
For I shall send.
DUKE OF YORK:
A noble lord 'gainst your father's brother's life,
And that thy father is that our love I.
DUCHESS OF YORK:
This is dear earnest:
I have a noble princely father, my lord,
To help that I have done to thee mercy.
...
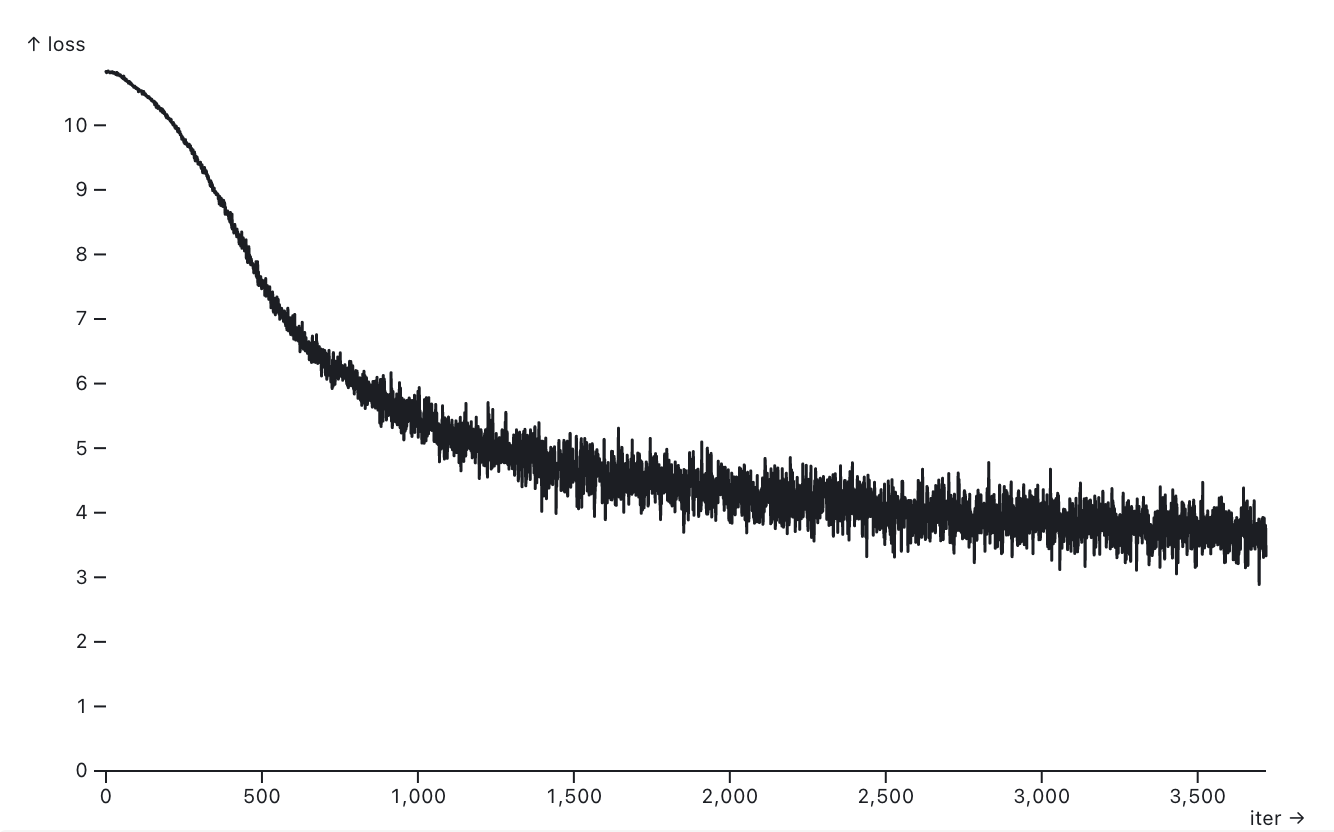
Plotting the loss
While the model is training, it constantly spits out log lines that look like this:
iter 3347: loss 3.4083, time 147.35ms
iter 3348: loss 3.7375, time 143.69ms
iter 3349: loss 3.8182, time 146.72ms
iter 3350: loss 3.8126, time 149.67ms
iter 3351: loss 3.5622, time 148.11ms
I decided to plot these on a chart to see how the loss was changing over time.
I built an Observable notebook for this: https://observablehq.com/@simonw/plot-loss-from-nanogpt
Hit Ctrl+A in your terminal to select everything, then paste it into that notebook.
Here's the result I get for 3,719 iterations:
Related
Created 2023-02-01T11:33:58-08:00 · Edit