Use DuckDB to convert parquet to JSON and then open it in Datasette Lite
pickapic.io is a new tool funded by stability.ai which asks people to generate and then vote on images in order to provide data to be used for fine tuning an open source image generation model.
The data collected by the tool is periodically published here on Hugging Face, and can be exported as a 12MB (currently) parquet file.
I wanted to explore it in Datasette Lite, which doesn't (yet) handle Parquet - so I needed to convert Parquet into JSON.
Installing DuckDB
DuckDB can do this! I installed it using Homebrew:
brew install duckdb
Converting the data
I downloaded the Parquet file like this:
wget https://huggingface.co/datasets/yuvalkirstain/PickaPic-images/resolve/main/data/train-00000-of-00001-3fc76ae33f4e5a79.parquet
Then I ran duckdb to open an interactive session and count the records:
% duckdb
v0.7.1 b00b93f0b1
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D select count(*) from 'train-00000-of-00001-3fc76ae33f4e5a79.parquet';
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 109356 │
└──────────────┘
You can use single quotes to reference a Parquet file and query it like this:
select count(*) from
'train-00000-of-00001-3fc76ae33f4e5a79.parquet';To export to JSON, I ran this query:
copy (
select * from
'train-00000-of-00001-3fc76ae33f4e5a79.parquet'
) to 'train.json';The result was an 83MB JSON file - actually newline-delimited JSON, with one object per line.
% head -n 3 train.json
{"image_id":29493,"created_at":"2023-01-12 21:15:00.648197","image_uid":"e815662d-9709-4380-b4c1-96be11f07574","user_id":641,"prompt":"medieval protoss , glowing blue eyes","negative_prompt":"hood","seed":987113576,"gs":7.8482246,"steps":25,"idx":1,"num_generated":4,"scheduler_cls":"FlaxDPMSolverMultistepScheduler","model_id":"stabilityai/stable-diffusion-2-1","url":"https://text-to-image-human-preferences.s3.us-east-2.amazonaws.com/images/e815662d-9709-4380-b4c1-96be11f07574.png"}
{"image_id":29494,"created_at":"2023-01-12 21:15:00.675614","image_uid":"ca7cc72b-8271-4510-91b4-1f7a227fca96","user_id":641,"prompt":"medieval protoss , glowing blue eyes","negative_prompt":"hood","seed":987113576,"gs":7.8482246,"steps":25,"idx":2,"num_generated":4,"scheduler_cls":"FlaxDPMSolverMultistepScheduler","model_id":"stabilityai/stable-diffusion-2-1","url":"https://text-to-image-human-preferences.s3.us-east-2.amazonaws.com/images/ca7cc72b-8271-4510-91b4-1f7a227fca96.png"}
{"image_id":29495,"created_at":"2023-01-12 21:15:00.694099","image_uid":"60d04f96-1dd6-47ba-b314-5904718f2c3e","user_id":641,"prompt":"medieval protoss , glowing blue eyes","negative_prompt":"hood","seed":987113576,"gs":7.8482246,"steps":25,"idx":3,"num_generated":4,"scheduler_cls":"FlaxDPMSolverMultistepScheduler","model_id":"stabilityai/stable-diffusion-2-1","url":"https://text-to-image-human-preferences.s3.us-east-2.amazonaws.com/images/60d04f96-1dd6-47ba-b314-5904718f2c3e.png"}
Uploading that to S3 for Datasette Lite
Datasette Lite can open newline-delimited JSON files, provided they are hosted online somewhere with open CORS headers.
Normally I'd use a GitHub Gist for this, but 80MB is too large for that - so I uploaded it to an S3 bucket instead.
I used my s3-credentials tool for that. First I created a bucket:
s3-credentials create simonw-open-cors-bucket --public -cThen I set an open CORS policy for that bucket:
s3-credentials set-cors-policy simonw-open-cors-bucketThen uploaded the JSON file:
s3-credentials put-object simonw-open-cors-bucket PickaPic-images.json train.jsonThe URL for that file is now: https://s3.amazonaws.com/simonw-open-cors-bucket/PickaPic-images.json (warning: 80MB)
Opening it in Datasette Lite
Datasette Lite runs the Datasette Python web application entirely in the browser thanks to WebAssembly.
I can construct a URL to it that loads this file. Note that it's an 80MB file and needs to be fetched by the browser, so following this link will fetch around 90MB of data.
Here's the full URL I constructed (after some iteration):
This is doing a few things.
-
?install=datasette-render-image-tagstells Datasette Lite to install the datasette-render-image-tags plugin, which looks for any URLs ending in.png(or.gifor.jpg) and turn them into embedded image elements. -
&json=https://s3.amazonaws.com/simonw-open-cors-bucket/PickaPic-images.jsontells Datasette Lite to load the JSON data from that URL. This works for JSON arrays of objects and for newline-delimited JSON, like we have here. -
#/data?sql=select...tells Datasette Lite to navigate to the SQL querying interface and run the specified query. -
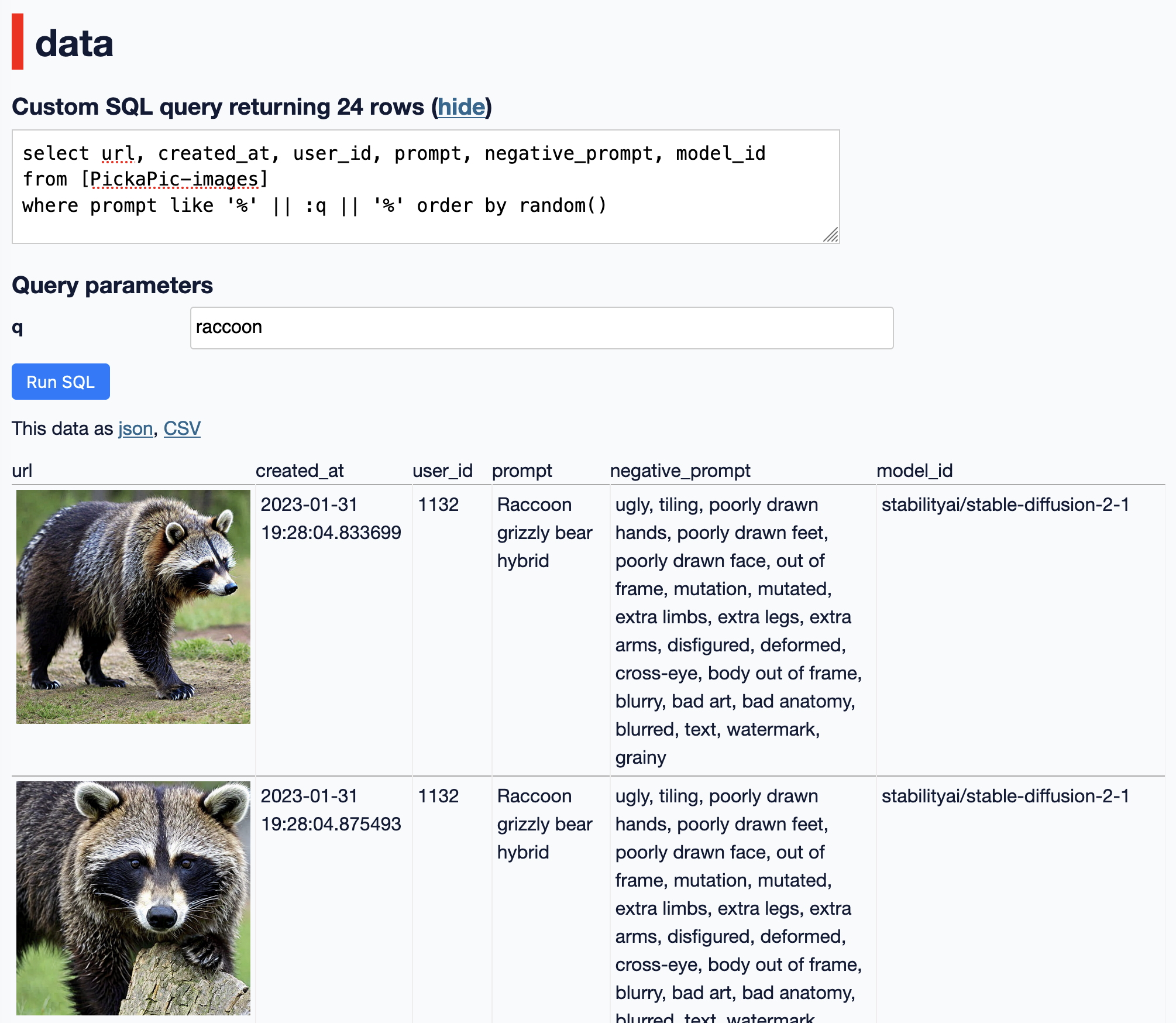
&q=raccoonat the end is a query parameter that will be used as part of the query.
The SQL query it executes looks like this:
select url, created_at, user_id, prompt, negative_prompt, model_id
from [PickaPic-images]
where prompt like '%' || :q || '%' order by random()This runs a like search for the given term and returns the results in a random order. I like order by random() for interfaces that are designed just for exploring a new dataset.
The end result looks like this:
Related
Created 2023-03-21T15:49:33-07:00, updated 2023-03-21T16:21:43-07:00 · History · Edit