Scraping the Sky News Westminster Accounts, a Flourish application
Sky News in partnership with Tortoise published a fantastic piece of investigative data reporting: the Westminster Accounts, a database of money in UK politics that brought together data from three different sources and make it explorable.
You can explore the data in their interactive here. It's really well built.
Tortoise have a comprehensive explanation of their methodology that is well worth reading.
The interactive is built with Flourish. I decided to see if I could get the raw data back out again.
Extracting the data with copy and paste
The full page interactive is at https://flo.uri.sh/visualisation/11927686/embed?auto=1 - I opened that in the Firefox DevTools and started poking around.
The data seemed to exist in the window.template.data variable. I ran this:
Object.keys(window.template.data)And it output:
["appg_donations", "appgs", "member_appgs", "members", "parties", "party_donations", "payments"]
Each of those keys is a JSON list of objects of different types - exactly the raw data I was looking for.
I started by copying and pasting that data out, using the copy() function in the Firefox JavaScript console:
copy(JSON.stringify(window.template.data.appg_donations))I then pasted that into a file called appg_donations.json.
I repeated that for appgs, member_appgs, parties, party_donations and payments.
But when I tried it against window.template.data.members, I got an error:
Uncaught TypeError: cyclic object value
That turned out to be a nested object with cyclic references, which JSON.stringify() couldn't handle.
After some poking around I decided this subset would do the trick:
copy(
JSON.stringify(
window.template.data.members.map(
({ id, name, gender, constituency, party_id, short_name, status }) => ({
id,
name,
gender,
constituency,
party_id,
short_name,
status,
})
)
)
);Turning that into a database
I now had JSON files for each of the seven tables that made up the data.
I used the following commands to import them into a SQLite database using sqlite-utils:
sqlite-utils insert sky-westminster-files.db appg_donations appg_donations.json --pk id
sqlite-utils insert sky-westminster-files.db appgs appgs.json --pk id
sqlite-utils insert sky-westminster-files.db members members.json --pk id
sqlite-utils insert sky-westminster-files.db parties parties.json --pk id
sqlite-utils insert sky-westminster-files.db party_donations party_donations.json --pk donation_id
sqlite-utils insert sky-westminster-files.db payments payments.json --pk id
sqlite-utils insert sky-westminster-files.db member_appgs member_appgs.jsonI ran this a couple of times to figure out the primary keys so I could specify them with --pk id.
When I explored the resulting database using Datasette it became clear that some columns were foreign keys to other tables. I figured out what those were and used the following commands to add those to the database:
sqlite-utils add-foreign-key sky-westminster-files.db \
appg_donations appg_name appgs id
sqlite-utils add-foreign-key sky-westminster-files.db \
member_appgs appg_name appgs id
sqlite-utils add-foreign-key sky-westminster-files.db \
member_appgs member_id members id
sqlite-utils add-foreign-key sky-westminster-files.db \
members party_id parties id
sqlite-utils add-foreign-key sky-westminster-files.db \
party_donations party_id parties id
sqlite-utils add-foreign-key sky-westminster-files.db \
payments member_id members idThe result was a 5.6MB SQLite database. I uploaded a copy of that here: https://static.simonwillison.net/static/2023/sky-westminster-files.db
I wanted to open it in Datasette Lite - so I dumped out the raw SQL using this command:
sqlite-utils dump sky-westminster-files.db > dump.sql
And put that in this Gist.
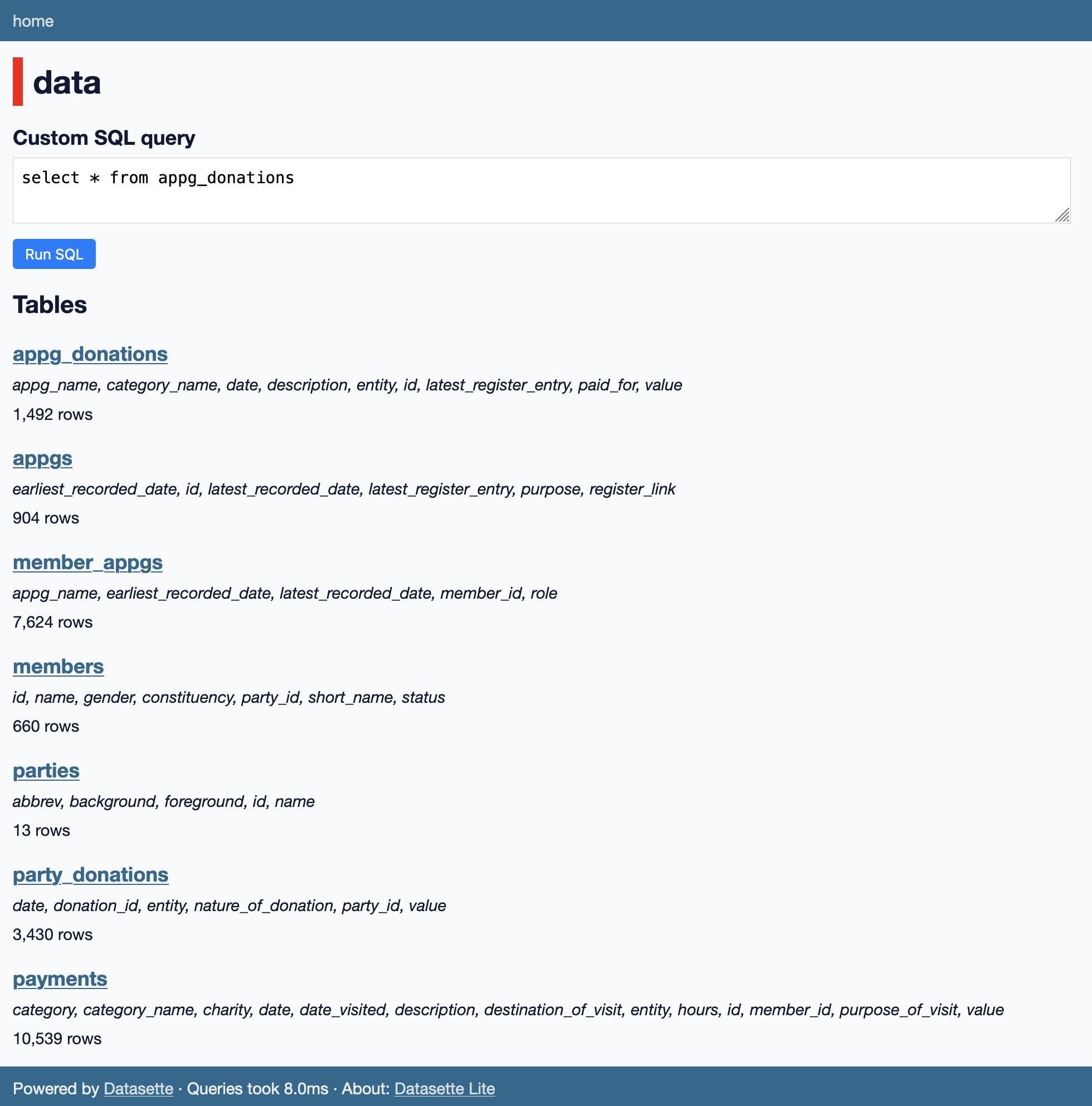
Now I can open it in Datasette Lite like so:
https://lite.datasette.io/?sql=https://gist.github.com/simonw/ee4d5938016b10c490f7efa03c4bf185
Automating the data extraction
One last step: I decided to script the data extraction itself, using shot-scraper javascript.
I built a new tool to help with that - json-to-files - which accepts a JSON object mapping filenames to content and writes those files to disk.
With that in place I could run this:
pip install shot-scraper json-to-files
shot-scraper install
And then use shot-scraper to scrape the page and write the data to disk like this:
shot-scraper javascript 'https://flo.uri.sh/visualisation/11927686/embed?auto=1' '({
"appg_donations.json": JSON.stringify(window.template.data.appg_donations, null, 2),
"appgs.json": JSON.stringify(window.template.data.appgs, null, 2),
"member_appgs.json": JSON.stringify(window.template.data.member_appgs, null, 2),
"parties.json": JSON.stringify(window.template.data.parties, null, 2),
"party_donations.json": JSON.stringify(window.template.data.party_donations, null, 2),
"payments.json": JSON.stringify(window.template.data.payments, null, 2),
"members.json": JSON.stringify(
window.template.data.members.map(
({ id, name, gender, constituency, party_id, short_name, status }) => ({
id,
name,
gender,
constituency,
party_id,
short_name,
status,
})
), null, 2
)
})' | json-to-files -d sky-westminster-filesThe result was sky-westminster-files directory containing the seven JSON files.
Related
Created 2023-01-10T12:31:50-08:00, updated 2023-01-30T11:04:55-08:00 · History · Edit